HorizontalPodAutoscaler
在Kubernetes 中HorizontalPodAutoscaler自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与垂直(Vertical)扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且Pod的数量高于配置的最小值,HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
水平Pod自动扩缩不适用于无法扩缩的对象: 例如DemonSet这种
我们可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
HorizontalPodAutoscaler 是如何工作的
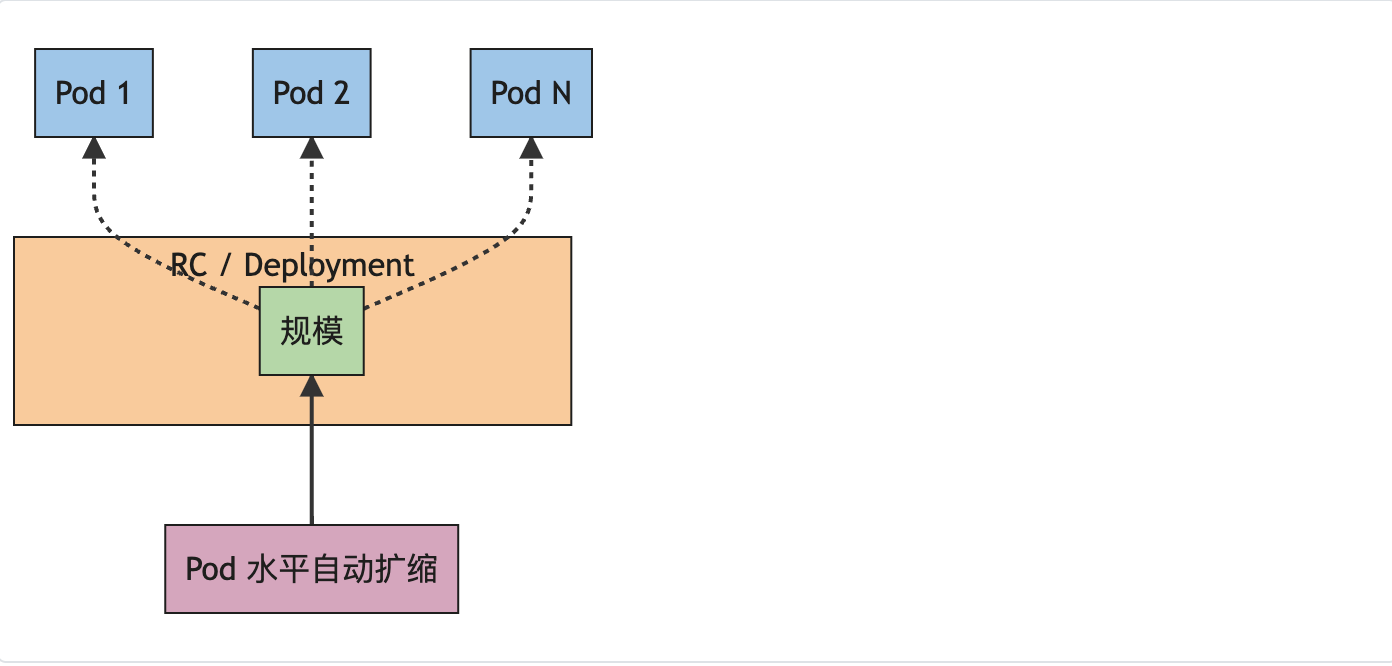
Kubernetes 将水平 Pod 自动扩缩实现为一个间歇运行的控制回路(它不是一个连续的过程)。间隔由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)
- 对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况, 并计算资源使用率。如果设置了 target 值,将直接使用原始数据(不再计算百分比)。 接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
- 如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
- 如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。 这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。 在
autoscaling/v2版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。
HorizontalPodAutoscaler的常见用途是将其配置为从聚合 API (metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。 metrics.k8s.io API 通常由名为Metrics Server的插件提供,需要单独启动。有关资源指标的更多信息, 请参阅 Metrics Server。
Metrics-Server
在 HPA 的第一个版本中,我们需要 Heapster 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了:
https://api.k8s.io:8443/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
比如当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
聚合 API
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样我们就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。这样这个聚合层就带来了很多好处:
- 增加了 API 的扩展性,开发人员可以编写自己的 API 服务来暴露他们想要的 API。
- 丰富了 API,核心 kubernetes 团队阻止了很多新的 API 提案,通过允许开发人员将他们的 API 作为单独的服务公开,这样就无须社区繁杂的审查了。
- 开发分阶段实验性 API,新的 API 可以在单独的聚合服务中开发,当它稳定之后,在合并会 APIServer 就很容易了。
- 确保新 API 遵循 Kubernetes 约定,如果没有这里提出的机制,社区成员可能会被迫推出自己的东西,这样很可能造成社区成员和社区约定不一致。
部署HPA
我们要使用 HPA,就需要在集群中安装 Metrics Server 服务,要安装 Metrics Server 就需要开启 Aggregator,因为 Metrics Server 就是通过该代理进行扩展的,不过我们集群是通过 Kubeadm 搭建的,默认已经开启了,如果是二进制方式安装的集群,需要单独配置 kube-apsierver 添加如下所示的参数:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
Aggregator 聚合层启动完成后,就可以来安装 Metrics Server 了,我们可以获取该仓库的官方安装资源清单:
- 官方仓库地址:https://github.com/kubernetes-sigs/metrics-server
# 请修改镜像为: registry.aliyuncs.com/google_containers/metrics-server:v0.6.2
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
如果出现x509: cannot validate certificate for 10.151.30.22 because it doesn’t contain any IP SANs这种错误,因为部署集群的时候,CA 证书并没有把各个节点的 IP 签上去,所以这里 Metrics Server 通过 IP 去请求时,提示签的证书没有对应的IP所导致的,我们可以添加一个--kubelet-insecure-tls参数跳过证书校验:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
# 修改完成后记得部署
kubectl apply -f components.yaml
验证HPA是否安装成功,现在我们可以通过 kubectl top 命令来获取到资源数据了,证明 Metrics Server 已经安装成功了。
[root@Online-Beijing-master1 ~]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
online-beijing-master1 82m 1% 1970Mi 12%
online-beijing-master2 59m 0% 1379Mi 8%
online-beijing-master3 61m 0% 1389Mi 8%
online-beijing-node1 35m 0% 1957Mi 12%
online-beijing-node2 33m 0% 1875Mi 11%
online-beijing-node3 35m 0% 1045Mi 6%
首先我们先创建一个deployment,准备对他进行HPA
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo-nginx
namespace: default
labels:
k8s-app: hpa-demo-nginx
spec:
replicas: 1
selector:
matchLabels:
k8s-app: hpa-demo-nginx
template:
metadata:
name: hpa-demo-nginx
labels:
k8s-app: hpa-demo-nginx
spec:
containers:
- name: hpa-demo-nginx
image: nginx:latest
resources:
requests:
cpu: 10m
memory: 100Mi
securityContext:
privileged: false
创建基于CPU的自动扩容
我们这次只针对CPU进行操作,后续我们会根据更多的自定义资源来进行扩缩容。
现在我们来创建一个HPA,可以使用kubectl autoscale命令来创建:
kubectl autoscale deployment hpa-demo-nginx --cpu-percent=10 --min=1 --max=6
此命令创建了一个关联资源hpa-demo-nginx 的HPA,最小的 pod 副本数为3,最大为6。HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。
[root@Online-Beijing-master1 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo-nginx Deployment/hpa-demo-nginx <unknown>/10% 1 6 0 8s
接下来对Pod进行压力测试,不断的去请求当前hpa-demo-nginxPod的IP
kubectl run -i --tty load-generator --image=busybox /bin/sh
while true; do wget -q -O- http://10.10.180.71; done
正常可以看到HPA已经正常工作了,Pod的副本数量已经分配到了我们当时指定的6个
[root@Online-Beijing-master1 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo-nginx Deployment/hpa-demo-nginx 78%/10% 1 6 6 4m20s
从kubernetesv1.12版本开始,我们可以通过设置kube-controller-manager的--horizontal-pod-autoscaler-downscale-stabilization参数来设置一个持续时间,指的是用于当前扩容操作完成后,多久以后才进行一次缩放操作。默认为5分钟,也就是五分钟后才会进行缩放。
创建一个基于内存的自动扩容
跟CPU是一样的,都是基于metrics-server获取指标然后进行扩容。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
namespace: default
labels:
k8s-app: hpa-mem-demo
spec:
replicas: 1
selector:
matchLabels:
k8s-app: hpa-mem-demo
template:
metadata:
name: hpa-mem-demo
labels:
k8s-app: hpa-mem-demo
spec:
containers:
- name: hpa-mem-demo
image: nginx:latest
resources:
requests:
memory: 20Mi
cpu: 10m
securityContext:
privileged: true
volumeMounts:
- name: mount-configmap
mountPath: /etc/script
volumes:
- name: mount-configmap
configMap:
name: increase-mem-config
这里和前面普通的应用有一些区别,我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:(increase-mem-cm.yaml)
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置。现在我们直接创建上面的资源对象即可
kubectl apply -f hpa-demo-mem.yaml
kubectl apply -f increase-mem-config.yaml