为什么需要kubernetes?
- 大规模多节点容器调度
- 快速扩缩容
- 故障自愈
- 弹性伸缩
- 技术趋势
- 一致性、不锁定
早期型多的一些服务都属于单体服务、单节点、单进程的一种单体服务架构,后续随着技术的发展衍生出了容器技术。容器技术其实也不能满足我们的多节点、分布式的应用架构体系,从而衍生出了
kubernetes容器编排引擎。
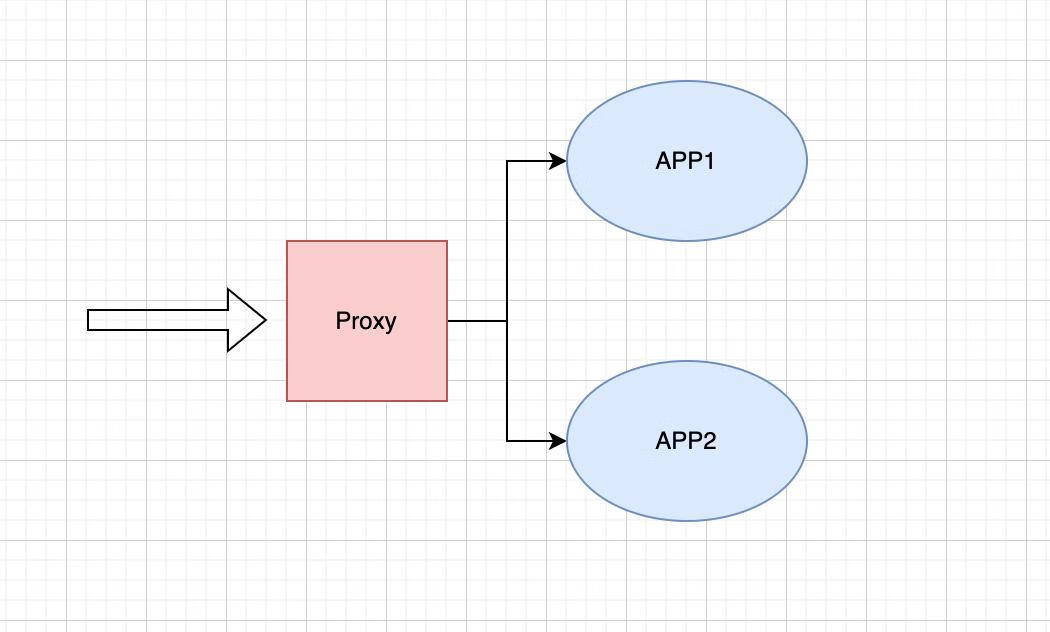
那么我们来看一下早期单体容器架构
其实对于容器化技术带来了那些优势呢?
- 其实我觉得容器化带来的最大的优势就是交付和部署的优势
那么由于Docker的容器镜像可以在A、B、C任意一台机器上运行,那么是否可以当A机器所运行的镜像挂掉以后自动的帮我在B机器上进行重启呢?
okey 带着这个问题 一起往下进行。
kubernes组件
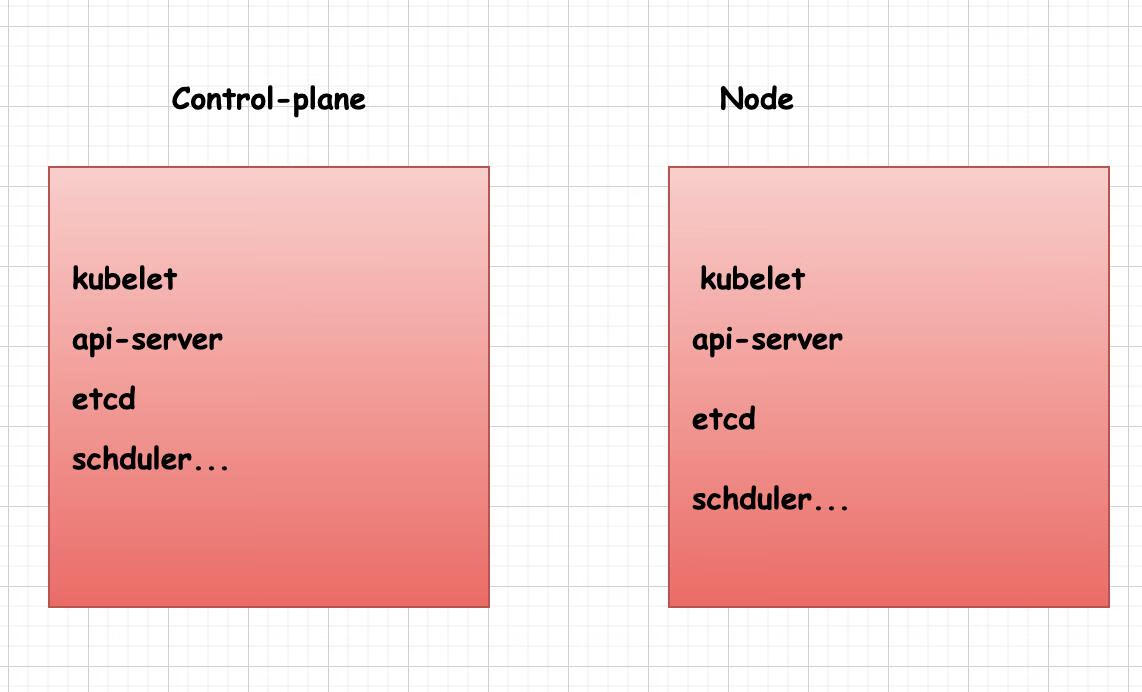
先看一张官方给出的kubernetes的架构图 图中列出了kubernetes的组成以及相对应的组件
- ControlPlane: 控制平面节点
- Node: 工作节点
- Kubelet: 用于控制
staticPod,其主要就是用来控制静态Pod,因为静态Pod不受ApiServer的影响。
Oh 不插一句嘴 学到了一个新的命令
# jq命令是一个用于处理json的命令
kubectl get deploy wecho-canary -o json | jq .spec
okey 继续…
我们时长谈起到的control-plane实际上并不是一台机器他只是一个抽象出来的概念,实际上我们是在说所谓的control-plane层面的组件。也就是说这些组件可以运行在控制面的机器上同时也可以运行在Node机器上
kubernetes核心概念
ResourceObject: 是我认为相对而言kubernetes集群当中比较核心的资源对象,其实也就是我们所说的Pod、Deployment、Daemonset等kubernetes的资源类型 对于一个Pod而言,kubernetes对其定义的键值无非以下的几种
[root@Online-Beijing-master1 ~]# kubectl get deploy wecho-canary -o json | jq keys
[
"apiVersion",
"kind",
"metadata",
"spec", // spec描述的是Pod预期的状态
"status"
]
你可以通过kubectl api-resource来获取kubernetes相对应的资源类型。
kubernets的资源提交
我们平时使用的kubectl run nginx-$RANDOM --image="nginx:alpine"究竟是执行了什么样的内容?
正常来说Api-Server本身就是服务,那么当我把请求发送给Api-Server的时候,我是以什么样的请求内容进行了提交?那Api-Server接收了我的请求内容又对我的请求内容做出了什么样的处理呢?
首先我们来看实际作为客户端,也就是client端提交的请求
# 可以通过--dry-run=client来模拟客户端提交的请求内容
kubectl run nginx-$RANDOM --image="nginx:alpine" --dry-run=client -ojson -v6
正常的返回响应应该如下,这是一个我们正常通过kubelet创建一个Pod所发送的请求体内容,但作为clinet只会在我们本地进行处理,所以你也可以看到返回的结构内容中带有I1108 21:54:49.922270 1219589 loader.go:374] Config loaded from file: /root/.kube/config,也就证明了它并没有像Api-Server发送任何请求,只是读取了相关的配置信息。
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "nginx-27147",
"creationTimestamp": null,
"labels": {
"run": "nginx-27147"
}
},
"spec": {
"containers": [
{
"name": "nginx-27147",
"image": "nginx:alpine",
"resources": {}
}
],
"restartPolicy": "Always",
"dnsPolicy": "ClusterFirst"
},
"status": {}
}
很好上面我们模拟了一个client端所生产的内容,那么下面我们看看当实际发送给Api-Server的时候产生了哪些内容
kubectl run nginx-$RANDOM --image="nginx:alpine" --dry-run=server -ojson -v6
我们可以清晰地看到日志的输出
- 首先第一步加载了kubernetes相关的配置文件信息。
- 发送了相关请求(盲猜应该是验证api-server是否正常)
- 向
https://resk8s.api.beijing.io:8443/api/v1/namespaces/default/pods?dryRun=All&fieldManager=kubectl-run发送了POST请求用于创建Pod
I1108 21:58:14.866131 1221713 loader.go:374] Config loaded from file: /root/.kube/config
I1108 21:58:14.884329 1221713 round_trippers.go:553] GET https://resk8s.api.beijing.io:8443/openapi/v2?timeout=32s 200 OK in 15 milliseconds
I1108 21:58:14.946553 1221713 round_trippers.go:553] POST https://resk8s.api.beijing.io:8443/api/v1/namespaces/default/pods?dryRun=All&fieldManager=kubectl-run 201 Created in 15 milliseconds
事实上我们由此可见发送到Api-Server的请求内容多了很多东西
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "nginx-14483",
"namespace": "default",
"uid": "d27e1836-8bac-40d4-805b-420f4bca4ee1",
"creationTimestamp": "2023-11-08T14:05:36Z",
"labels": {
"run": "nginx-14483"
},
"annotations": {
"kubernetes.customized/fabric-networks": "default"
}
},
"spec": {
"volumes": [
{
"name": "kube-api-access-vwtvp",
"projected": {
"sources": [
{
"serviceAccountToken": {
"expirationSeconds": 3607,
"path": "token"
}
},
{
"configMap": {
"name": "kube-root-ca.crt",
"items": [
{
"key": "ca.crt",
"path": "ca.crt"
}
]
}
},
{
"downwardAPI": {
"items": [
{
"path": "namespace",
"fieldRef": {
"apiVersion": "v1",
"fieldPath": "metadata.namespace"
}
}
]
}
}
],
"defaultMode": 420
}
}
],
"containers": [
{
"name": "nginx-14483",
"image": "nginx:alpine",
"resources": {},
"volumeMounts": [
{
"name": "kube-api-access-vwtvp",
"readOnly": true,
"mountPath": "/var/run/secrets/kubernetes.io/serviceaccount"
}
],
"terminationMessagePath": "/dev/termination-log",
"terminationMessagePolicy": "File",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Always",
"terminationGracePeriodSeconds": 30,
"dnsPolicy": "ClusterFirst",
"serviceAccountName": "default",
"serviceAccount": "default",
"securityContext": {},
"schedulerName": "default-scheduler",
"tolerations": [
{
"key": "node.kubernetes.io/not-ready",
"operator": "Exists",
"effect": "NoExecute",
"tolerationSeconds": 300
},
{
"key": "node.kubernetes.io/unreachable",
"operator": "Exists",
"effect": "NoExecute",
"tolerationSeconds": 300
}
],
"priority": 0,
"dnsConfig": {
"options": [
{
"name": "single-request-reopen"
}
]
},
"enableServiceLinks": true,
"preemptionPolicy": "PreemptLowerPriority"
},
"status": {
"phase": "Pending", // 可以看到当前处于Pending阶段
"qosClass": "BestEffort"
}
}
另外: 当你需要创建资源类型的时候,我并不建议你从头开始去编写相关文件,可以灵活的应用
kubectl run来进行填充相关的字段信息。
kubernetes设计理念
- 声明式:典型就是在资源文件中进行声明
- 无侵入性
- 可移植: 所有符合kubernetes标准的kubernetes平台都可以进行迁移
- 显示接口:所有的操作都是开放性的,不会存在私有接口,无论是
Api-Server或者Clinet-go所操作的接口都是一模一样的。
创建资源的工作流程
- 首先当用户的请求进入到
Api-Server后会进入到Authorization认证授权的处理接口实际上就是加载我们的config配置文件,其具体代码在loader.go:372进行实现
服务发现原理和应用
kubernetes中Pod的通信
- 每个Pod都有自己的IP分配
- Pod间的可以通过IP进行通信
- Pod的IP是可变的
- Pod的IP通常不能被提前获取,一般都是网络插件进行分配
kubernetes的Service通信
它是一种抽象,帮助你将 Pod 集合在网络上公开出去。 每个 Service 对象定义端点的一个逻辑集合(通常这些端点就是 Pod)以及如何访问到这些 Pod 的策略。
我们通常可以使用以下命令来简单的暴露一个Service
kubectl expose deploy/nginx --port=80
通常来说我们访问某个服务都是访问服务的IP地址,当然了,在kubernetes中访问Service对应的地址也可以访问到服务
[root@Online-Beijing-master1 ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wecho-canary ClusterIP 10.10.166.79 <none> 80/TCP,9113/TCP 69d
kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 279d
实际上也就是说当我需要访问wecho-canary这个服务的时候,我无需关心他后端end如何进行变化,我只需要记住访问wecho-canary的Service所给出的ClusterIP即可进行访问到相应的服务。
另外的一种方式就是通过我们的Service名称来进行访问,下面说一下具体是如何通过Service名称进行访问的。
我们假设使用上面的
wecho-canary名称进行一次访问
curl -v wecho-canary # 假设访问正常
很简单,大家都知道当我们访问一个域名的时候背后肯定又DNS服务器来解析其所对应的IP地址,那么其实在kubernetes当中也有一个内部的DNS服务器,名字叫做kube-dns
我们可以通过kubectl get svc -A 进行查看,其中所指定的10.10.0.10就是我们kube-dns的IP地址.
kube-system kube-dns ClusterIP 10.10.0.10 <none> 53/UDP,53/TCP,9153/TCP 279d
看到我们kube-dns有以下端点
[root@Online-Beijing-master1 ~]# kubectl get ep -n kube-system | grep kube-dns
kube-dns 10.10.151.159:53,10.10.4.95:53,10.10.151.159:53 + 3 more... 279d
kube-dns-upstream 10.10.151.159:53,10.10.4.95:53,10.10.151.159:53 + 1 more... 81d
其次可以看到我们容器内所对应的resolv.conf所写内容的配置文件
search jiashicang.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5 single-request-reopen
由于我使用了NodeLocalDns所以我这个地方的nameserver不太一样,关于NodeLocalDns我们后续再说。
总结以下几点:
- 当我们访问
wecho-canary的时候实际上是访问了wecho-canary.default.cluster.local.svc,即ServiceName.Namespace.cluster.local.svc- 所有的解析域名请求都会请求到
kube-dns当中,当kube-dns无法完成解析的时候,我们会将请求forward到本地的解析文件当中,如果本地解析文件也无法解析则认为失败。典型的就是超时、无法解析等问题。- Service通过监视API server的数据变化来感知后端Pod的变化,并及时更新负载均衡规则。具体来说,Kubernetes ApiServer负责管理集群状态,它会记录每一个对象(包括Pod)的Spec和Status。Service对象使用ApiServer的watch接口,监视后端关联Pod对象的变化事件。比如Pod实例加入或销毁时,ApiServer会主动通知Service。一旦检测到Pod变化,Service会立即使用新的Pod列表,重新计算并更新自己负载均衡的端口转发规则。例如使用iptables规则或IPVS表更新后端目标地址。这样,无论Pod是动态伸缩还是故障转移,Service都能即时感知,保持负载均衡入口地址的高可靠性。这就是Service如何实现动态更新负载均衡规则的原理。
Service类型
- ClusterIP: 通过集群的内部IP公开
Service,选择该值时Service只能够在集群内部访问。这也是你没有为服务显式指定type时使用的默认值。 - NodePort: 通过每个节点上的IP和静态端口
NodePort公开 Service。为了让Service可通过节点端口访问,Kubernetes 会为 Service配置集群IP地址, 相当于你请求了type:ClusterIP的服务。 - LoadBalancer:使用云平台的负载均衡器向外部公开
Service,一般来说都用在云厂商才会使用LoadBalancer - ExternalName:将服务映射到
externalName字段的内容 例如,映射到主机名:api.foo.bar.example,该映射将集群的 DNS 服务器配置为返回具有该外部主机名值的CNAME记录。
常用的暴露Service的方法
kubectl expose deploy/nginx --port=80 --type=NodePort
哦,对了,推荐一个开源的LB插件
- Metallb: Github
服务发现和流量路由
总的来说我们分为一下几点吧
- Pod之间的流量通信:
- IP直连的方式: 不推荐这种方式,因为Pod的IP严格意义上来说对于服务版本更新生命周期相对较短。
- ClusterIP: 相对于比较推荐通过指定ServiceName的方式来绑定活着监听某种服务
- 外部访问Pod的通信
- NodePort: 通过暴露外部端口的方式来进行Pod的访问
- LoadBalancer: 通过对Service绑定LB的方式进行Pod的访问
- Pod访问外部通信:
- ExternalName: 将 Service 映射到 DNS 名称
- HeadlessService: 当你不需要负载均衡,也不需要单独的 ServiceIP,你可以使用
HeadlessService
# 下面是ExternalName的简单实例
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
一般来说Kubernetes的内部DNS记录有两种规范
PodIP.Namespace.pod.cluster-domain.example
---
ServiceName.Namespace.svc.cluster-domain.example




















