访问控制概览
Kubernetes API的每个请求都会经过多阶段的访问控制之后才会被接受,这一阶段包括认证、授权、以及准入控制(Admission Control)等
认证插件
- x509证书:使用x509证书只需要API Server启动的时候配置
--client-ca-file=SOMEFILE。在证书认证的时候,其CN域名做用户名,而组织机构用作group名。 - 静态Token文件:使用静态Token文件认证只需要在API Server启动的时候配置
--token-auth-file=SOMEFILE。该文件为csv格式,每行至少包括三列token、username、user id - 引导Token
- 为了支持平滑的启动和引导新的集群,kubernetes包含了一种动态管理的持有令牌类型,称作启动引导令牌(Bootstrap Token)
- 这些令牌以
Secret的形式保存在kube-system的名称空间中,可以动态的管理和创建。 - 控制器管理器包含的TokenCleaner控制器能够在启动引导令牌过期时将其删除。
- 在使用kubeadm部署kubernetes的时候,可以通过
kubeadm token list进行查询。
- ServiceAccount:是kubernetes自动生成的,并且会自动挂载到容器的
/run/secrets/kubernetes.io/serviceaccount目录当中 - Webhook令牌身份认证
--authentication-token-webhook-config-file:指向一个配置文件,其中描述如何访问远程的Webhook服务--authentication-token-webhook-cache-ttl:用来设定身份认证决定的缓存时间。默认为2分钟。
静态Token用法
- 新建一个存放静态Token的目录
1 | mkdir -p /etc/kubernetes/auth |
- 将Token内容写入到文件当中
注意:该文件格式为CSV格式,其实你也可以随便写:happy:
1 | 描述: Token值 用户名称 用户ID 可选组名 |
假设这是我们请求名称空间的请求: curl -k -v -XGET -H "Authrization: Bearer kube-token" https://api.k8s.version.cn:6443/api/v1/namespaces/default
正常请求会返回,因为我没有创建这个kube-token
1 | { |
- 设置
API Server
注意: 操作的时候请备份你的API Server文件,这是一个好习惯.
1 | # vim /etc/kubernetes/manifests/kube-apiserver.yaml |
请您等待APIServer重启完成
当我们再次通过kube-token进行请求API Server 如果能成功识别到我们的用户即可,也就知道我们当前的用户为kubeadminer
1 | { |
UserAccount和ServiceAccount的区别
- UserAccount是与外部认证二次开发对接实现的,签发的Token是外部系统,每次APIServer需要带此Token请求外部认证服务器。
构建符合Kubernetes规范的认证服务
需要依照kubernetes规范,来构建认证服务进行认证
- URL:http://api.k8s.verbos/authenticate
- Method: POST(需要携带请求数据等等…)
- Input:
- Output:
WebHook认证用法
- 新建一个webhook-config.json
1 | { |
授权
授权主要是用于对于集群资源的访问控制,通过检查请求包含的相关属性值,与相对应的访问策略进行比较,API请求必须满足某些策略才能被处理。跟认证类似,kubernetes也支持多种授权机制,并支持同时开启多个插件授权(只要有一个通过即可)。如果授权成功,则用户的请求会发送到准入控制模块进行下一步处理。
kubernetes授权仅处理以下请求属性
- user、group、extra
- API、请求方法、请求路径
- 请求资源和子资源
- Namespace
- API Group
kubernetes支持以下授权插件
- ABAC
- RBAC
- WebHook
- Node
RBAC和ABAC
ABAC(Attribute Based Access Control)本来是不错的概念,但是在kubernetes中实现的比较难于管理和理解,而且需要对master所在节点进行SSH和文件系统权限,要使得对授权的变更生效还需要重启API Server
而RBAC的策略可以利用kubelet或者kubernetes API进行配置。RBAC可以授权给用户,让用户有权进行授权管理,这样就可以无需接触节点,直接进行授权管理。RBAC在kubernetes中被映射为API资源和操作。
Role和ClusterRole
Role(角色)是一系列特定角色权限的集合,例如一个角色可以包含读取Pod的权限和列出Pod的权限。
Role只能用来给某个特定的namespace中的资源作鉴权,对多namespace和集群级的资源活着是非资源类的API(如/healthz)使用ClusterRole
下面是一个简单的Role配置
1 | kind: Role |
下面是一个简单地ClusterRole配置
1 | kind: ClusterRole |
Binding
如果你想使全局生效可以使用kind: ClusterRoleBingding并且不写namespace
1 | kind: RoleBingding |
账户/组的管理
角色绑定(Role Bingding)是将角色中定义的权限赋予一个或者一组用户。
它包含主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用
组的概念
- 当外部系统认证对接的时候,用户信息可包含组信息,授权可以针对用户群组进行
- 当对
Service Account授权的时候,Group代表某个Namespace下的所有Service Account
如果针对群组授权
1 | kind: ClusterRoleBingding |
name: system:serviceaccounts表示当前是一个serviceaccount的格式进行命名的,并且授权给development这个Namespace里面所有的ServiceAccount
1 | kind: ClusterRoleBingding |
规划系统角色
User:
- 管理员:管理所有资源的权限
- 普通用户
- 是否有该用户创建的namespace下的所有object的操作权限?
- 对其他用户的namespace资源是否可读、是否可写
SystemAccount
- System是开发者创建应用后,应用于apiserver通讯需要的身份
- 用户可以创建自定的ServiceAccount,kubernetes也为每个namespace创建default
ServiceAccount Default ServiceAccount通常需要给定权限以后才能对API Server进行写操作
与权限相关的其他最佳实践
ClusterRole是非namespace绑定的,针对整个集群生效。
通常需要创建一个管理员角色,并且绑定给开发运营团队的成员ThirdPartyResource和CustomResourceDefinition是全局资源,普通用户创建以后需要管理员授权才能真正操作该对象。
ssh到master节点通过
insecure port访问apiserver可以绕过鉴权,当需要做管理操作又没有权限的时候可以使用(不推荐)
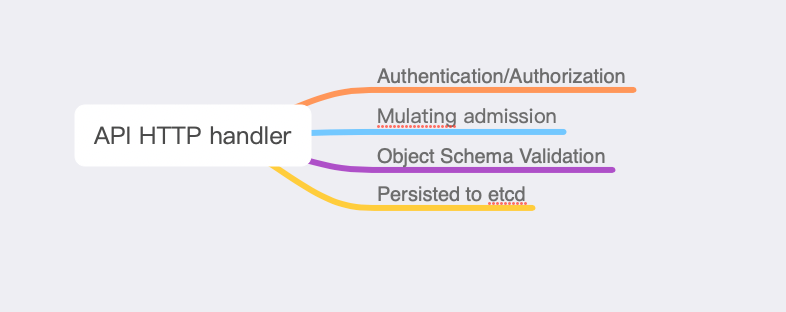
准入
准入控制
准入控制(Admission Control)在授权后对请求做进一步的验证或添加默认参数。不同于授权和认证只关心请求的用户和操作,准入控制还处理请求的内容,并且仅对创建、更新、删除或连接等有效,而对读操作无效。
准入控制支持同时开启多个插件,它们依次调用,只有全部插件都通过请求才可以进入系统。
配额管理
- 原因:资源有限,如何限定某个用户有多少资源
方案 - 预定义每个
Namespace的ResourceQuota,并且把spec保存为ConfigMap - 用户可以创建多少个Pod?
- BestEffortPod
- QuSPod
- 创建
ResourceQuota Controller: 一般用于监控namespace创建事件,当namespace创建的时候,在该namespace创建对应的ResourceQuota对象
1 | # 限制default namespace只能创建3个configmap |
准入控制插件
- AlwaysAdmit: 接受所有请求
- AlwaysPullImages: 总是拉新的镜像。一般用多租户场景
- DenyEscalatingExec: 禁止特权容器的exec和attach操作
- ImagePolicyWebhook: 通过webhook决定image策略,需要同时配置
--admission-control-config-file - ServiceAccount: 自动创建默认Service Account,并确保Pods引用的ServiceAccount已经存在
- SecurityContextDeny: 拒绝包含非法SecurityContext配置的容器
- ResourceQuota:限制Pod的请求不会超过配额,需要在namespace中创建
ResourceQuota对象 - MutatingWebhookConfiguration: 变形插件,支持对准入对象的修改
- ValidatingWebhoookConfiguration: 校验插件,只能对准入对象合法性进行校验
太多了 我就不一个一个写了…除了默认的准入控制插件以外,kubernetes预留了准入控制插件的扩展点,用户可以自定义准入控制插件
准入控制插件的演示
- MutatingWebhookConfiguration: 说白了就是对准入控制的对象内容进行修改
- 确保启用 MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook 控制器。 这里 是一组推荐的 admission 控制器,通常可以启用。
- 确保启用了
admissionregistration.k8s.io/v1的API
1 | git clone https://github.com/cncamp/admission-controller-webhook-demo.git |
这个暂且先不演示了…我也在研究哈哈
限流
漏斗算法
漏洞算法也很容易理解,请求进来以后首先进入漏斗里面,然后漏斗以恒定的速率将请求流出进行处理,从而起到平滑流量的作用。
当请求量过大,漏斗达到最大容量的时候会溢出,此时请求被丢弃
在系统看来,请求永远是以平滑的速率过来,从而起到了保护系统的作用
令牌桶算法
- 令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发
在令牌桶算法中,存在一个令牌桶,算法中存在一种机制以恒定的速率向令牌桶中放入令牌。 - 令牌桶也有一定的容量,如果满了的话令牌也无法放进去
- 当有请求进入的时候,会首先到令牌桶中去那令牌,则该请求会被处理,并消耗掉拿到的令牌,如果令牌桶为空,则请求会被丢弃。
API Server的限流
max-requests-inflight: 在给定的时间内的最大的non-mutating请求数max-mutating-requests-inflight: 在给定时间内的最大mutating请求数,调整apiserver的流控qos
反应出来的问题
- 粒度粗: 无法为不同用户,不同场景设置不同的限流
- 单队列:共享限流的窗口/桶,一个坏用户可能将整个系统堵塞
- 不公平:正常用户的请求会被排到队尾,无法及时处理请求而饿死
- 无优先级: 重要的系统指令一并被限流,系统故障难以恢复
| 默认值 | 节点数1000-3000 | 节点数>3000 | |
|---|---|---|---|
| max-requests-inflight | 400 | 1500 | 3000 |
| max-mutating-requests-inflight | 200 | 500 | 1000 |
API Priority and Fairness
- APF以更细颗粒度的方式对请求进行分类和隔离。
- 它还引入了空间有限的排队机制,因此在非常短暂的突发情况下,API服务器不会拒绝任何请求
- 通过使用公平排队技术从队列中分发请求,这样一个行为不佳的控制器就不会饿死其他控制器
- APF的核心
- 多等级
- 多队列
- APF 的实现依赖两个非常重要的资源
FlowSchema,PriorityLevelConfiguration - APF 对请求进行更细粒度的分类,每一个请求分类对应一个 FlowSchema (FS)
- FS 内的请求又会根据 distinguisher 进一步划分为不同的 Flow.
- FS 会设置一个优先级 (Priority Level, PL),不同优先级的并发资源是隔离的。所以不同优先级的资源不会相互排挤。特定优先级的请求可以被高优处理。
- 一个 PL 可以对应多个 FS,PL 中维护了一个
QueueSet,用于缓存不能及时处理的请求,请求不会因为超出 PL 的并发限制而被丢弃。 - FS 中的每个 Flow 通过 shuffle sharding 算法从 QueueSet 选取特定的 queues 缓存请求。
- 每次从 QueueSet 中取请求执行时,会先应用 fair queuing 算法从 QueueSet 中选中一个 queue,然后从这个 queue 中取出 oldest 请求执行。所以即使是同一个 PL 内的请求,也不会出现一个 Flow 内的请求一直占用资源的不公平现象。
通过kubectl get flowschema查看当前的flow
Flow Schema
FlowSchema会匹配一些入站请求,并将他们分配给优先级
每个入站请求都会有对应的FlowSchema测试是否匹配,首先从matchingPrecedence数值最低的匹配开始(我们认为这是逻辑上匹配最高),然后依次进行匹配,直到首个匹配出现.
1 | apiVersion: flowcontrol.apiserver.k8s.io/v1beta1 |
PriorityLevelConfiguration(优先级队列)
一个PriorityLevelConfiguration表示单个隔离类型。
每个PriorityLevelConfiguration对未完成的请求数有各自的限制,对排队中的请求数也有限制。
PriorityLevelConfiguration是可以被多个FlowSchema进行复用的
1 | apiVersion: flowcontrol.apiserver.k8s.io/v1beta1 |
可以通过kubectl get PriorityLevelConfiguration查看当前kubernetes中的优先级队列
- system: 用于 system:nodes 组(即 kubelet)的请求; kubelet 必须能连上 API 服务器,以便工作负载能够调度到其上。
- leader-election:
- 用于内置控制器的领导选举的请求 (特别是来自 kube-system 名称空间中 system:kube- controller-manager 和 system:kube-scheduler 用户和服务账号,针对 endpoints、 configmaps 或 leases 的请求)。
- 将这些请求与其他流量相隔离非常重要,因为领导者选举失败会导致控制器发生故障并重新启动,这反过来会导致新启动的控制器在同步信息时,流量开销更大。
- workload-high: 优先级用于内置控制器的请求
- workload-low: 优先级适用于来自任何服务帐户的请求,通常包括来自 Pods 中运行的控制器的所有请求。
- global-default: 优先级可处理所有其他流量,例如:非特权用户运行的交互式 kubectl 命令。
- exempt: 优先级的请求完全不受流控限制:它们总是立刻被分发。 特殊的 exempt FlowSchema把 system:masters 组的所有请求都归入该优先级组。
- catch-all:
- 优先级与特殊的 catch-all FlowSchema 结合使用,以确保每个请求都分类。
- 一般不应该依赖于 catch-all 的配置,而应适当地创建自己的 catch-all FlowSchema 和PriorityLevelConfigurations(或使用默认安装的 global-default 配置)。
- 为了帮助捕获部分请求未分类的配置错误,强制要求 catch-all 优先级仅允许5个并发份额,并且不对请求进行排队,使得仅与 catch-all FlowSchema 匹配的流量被拒绝的可能性更高,并显示 HTTP 429 错误。
1 | [root@Online-Beijing-master1 ~]# kubectl get PriorityLevelConfiguration |
详细说一下分流策略
- 根据
service-accounts的flow进行限制,distinguisherMethod根据不同的用户进行限流。 - 这一类的flow应该通过
priorityLevelConfiguration中定义的workload-low进行限流 - 通过
workload-low中定义的assuredConcurrencyShares设置当前请求的最大并发数量
高可用APIServer
搭建多租户的kubernetes集群
授信
- 认证: 禁止匿名访问,只允许可信用户做操作。
- 授权:基于授信的操作,防止多用户之间互相影响,比如普通用户删除Kubernetes核心服务,或者A用户删除或修改B用户 的应用。
隔离
- 可见行隔离:用户只关心自己的应用,无需看到其他用户的服务和部署。
- 资源隔离:有些关键项目对资源需求较高,需要有专业设备,不与其他人共享。
- 应用访问隔离:用户创建的服务,按照既定规则允许其他用户访问。
资源管理
- Quota管理: 谁能用多少资源
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。

等)


